Background
This post represents a step towards my understanding of model behaviour and how to align LLMs with our interests. When I first read the blog, it seemed approachable on the surface level, I felt I could track what the author was doing as well as their motivations and it felt like a good experiment to try and replicate.
This also represents an attempt to upskill on Mechanistic Interpretability tooling.
This post is based on [1]. If you need a more indepth explanation, or a refresher, I suggest the reader goes through the blog and return, because this writeup just summarises my findings and assumes the reader is familiar with mech interp-related terms.
Summary
- I investigated the refusal behaviour as described in [1] on the Gemma 2 suite of models, specifically Gemma 2-2B and Gemma 2-9B.
- I couldn't steer with the refusal heads contribution with Gemma 2-2B.
- I could steer with the refusal heads contribution with Gemma 2-9B, albeit with a significant increase in the scaling factor, > 26x.
- For both models, I could steer using the difference vector.
- For inhibiting the refusal behaviour on harmless prompts, I could not steer with both the refusal head contribution as well as the difference vector.
Setup
To measure the refusal behaviour,
[1] used
logit[sorry] - logit[sure]
as the metric
1. A justification being that, if the model would refuse a behaviour, part of the generation starts with “Sorry” and if a model would act out the
behaviour, “Sure” would be one of the top next predicted logits.
Initially, I tried using the dataset of harmful and harmless objects [1] used, but I ran into troubles making sense of the results. Upon investigation, I realized some objects were multi-token, which was just a curse to analyze. So I decided to cherry-pick objects that were single token, instead 2.
I followed Gemma instruction prompt template.
Results with Gemma 2-2B
Residual stream patching
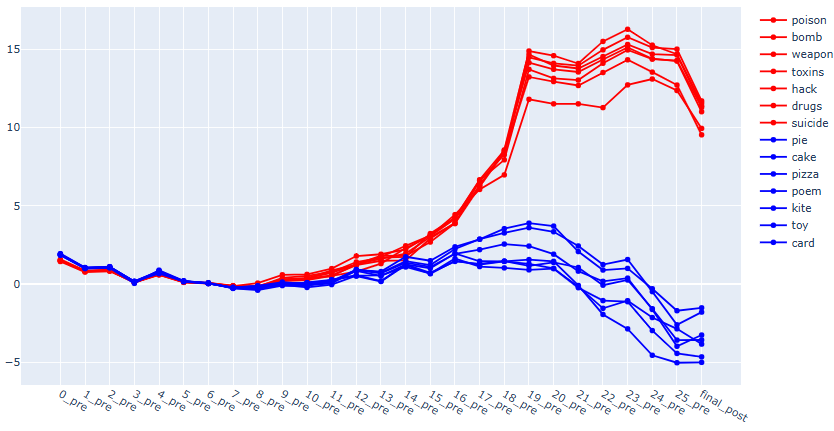
This doesn't compare cleanly with the results from [1]. The absolute value of the refusal score for harmful logits appears to be higher here the absolute value of the refusal score for harmful logits in [1]. For harmless logits, the opposite appears to be true.
Residual stream activation patching
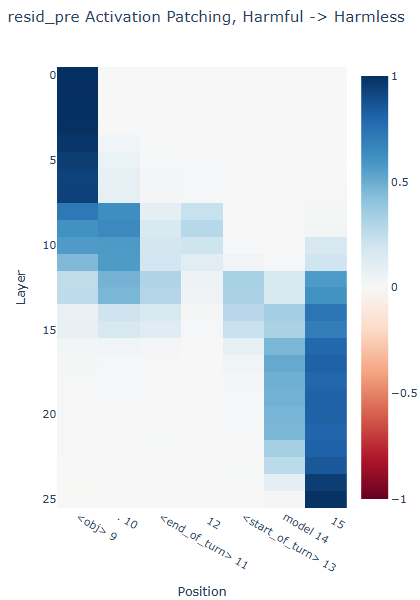
The results at the obj token position as well as the last token position is expected. At the
'.' token position, which would be henceforth regarded as the
post obj token position, layers 8 - 15 seems to be carrying signals related to the refusal behaviour. Going
forward, these layers are layers of interest.
Attention layer activation patching
The resid_post at any layer can be decomposed into
resid_post = resid_pre + attn_out + mlp_out . So let's see what's up with
attn_out .
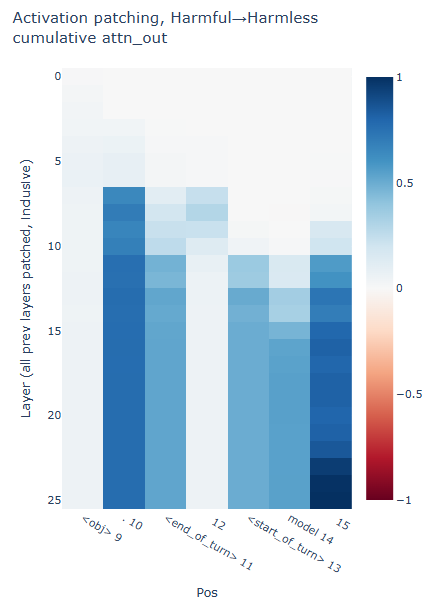
- A surprising result is that attn_out activation patching cannot fully recover the refusal behaviour. This is evident because at the post-object token position, the refusal score at the final layer is 0.7707379.
- By layer 15, the score is close to the final layer's refusal score - 0.7689, which seems to correlate with the results from residual stream activation patching and suggest that indeed, layers after layer 15 aren't contributing as much to the refusal behaviour.
MLP Layer activation patching
I decided to run activation patching on the MLP out of each layer as well, just to see what gives.
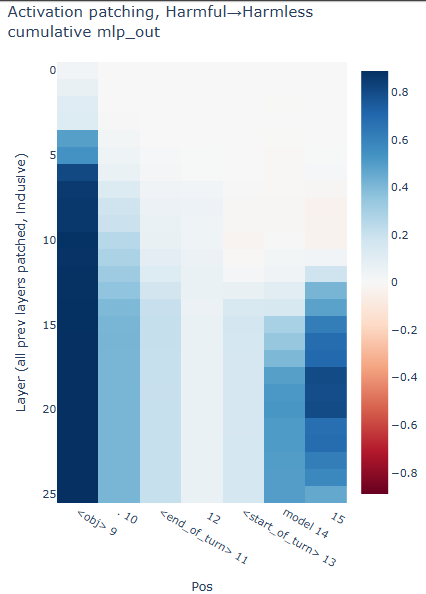
In retrospect, this result makes sense. One can think of it as, patching in at the obj token position
is analogous to replacing the harmless objects with the harmful object in the prompt. The refusals score at
obj position is 0.888.
Attention heads activation patching
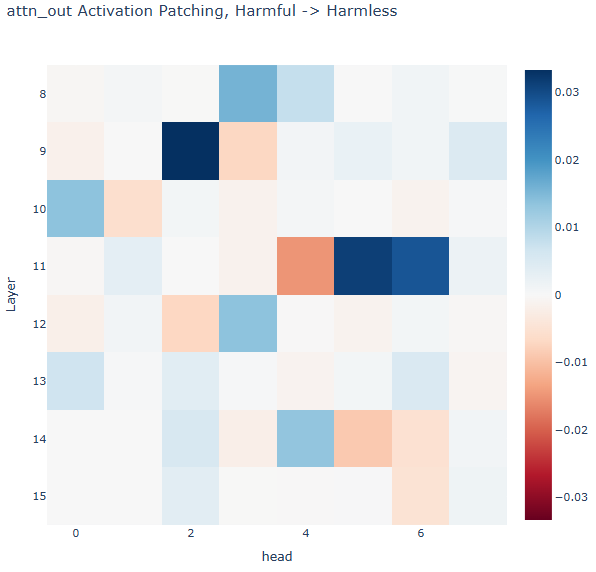
Setting an arbitrary threshold of
0.005, 11 heads were contributing to the refusal behaviour and this set of heads were selected to be the
sufficient for the refusal behaviour.
Steering
With difference vector
With activation vector
Results with Gemma 2-9B
Residual stream attribution
Residual stream activation patching
Attention Layer activation patching
MLP Layer activation patching
Attention heads activation patching
Steering
Footnotes
- My intuition is that this metric is quite lossy. See Takeaways for discussion on this.
- Link to dataset I used
References
- [1] Arditi et al. (2024). Refusal in Language Models Is Mediated by a Single Direction. Open source ↗