Replicating GraphRAG paper
a replication of 'From Local to Global'
Introduction
Microsoft research recently put out the GraphRAG paper
The summary of the paper is, we can structure the information in a
body of documents as a graph by thinking of every object in the
document as an entity and drawing it's relationship with other
entities. Once we have this graph, we can then reason over it to draw
insights and conclusions that otherwise we might not be able to draw.
In the paper, Microsoft research used podcast transcripts and news article as the knowledge source over which retrieval is done. I decided to use a podcast episode - specifically, Dwarkesh Patel's interview with Mechanistic Interpretability researchers Trenton Bricken and Sholto Douglas.
I would expect readers to be fairly familiar with the GraphRAG paper
Organizatinal notes
I encourage readers to probably read through the whole post and refer to this section from time to time.- For evaluation, I used one of the transcripts of Dwarkesh Patel's podcast as the knowledge source.
-
During development, I used a bunch of models to test out the
different components, but for the final graph index generation and
inference, I used
LLAMA 3.2 90B text-preview
, provided by Groq. That being said, Gemma 9B seems to perform the best on entity-relationship extraction I judged this because I have listened to the podcast episode and I was able to roughly access the quality of the generation for different models. . - I implemented a single hierarchy of clustering graph nodes and edges.
-
For the sake of optimizing for API the number of calls / requests to
Groq, I
implemented global search with a vectorDB, as opposed to LLM
summarization in the graphrag paper.
- I did not implement local search, covariates and a couple of other details that were token/api calls-expensive.
- LLM-derived Knowledge graph can be viewed here
-
Link to repository,
Link to streamlit chat interface
I did not exactly optimise the chat interface to be a conversational agent like SOTA chat agents. Ask questions, get a response.
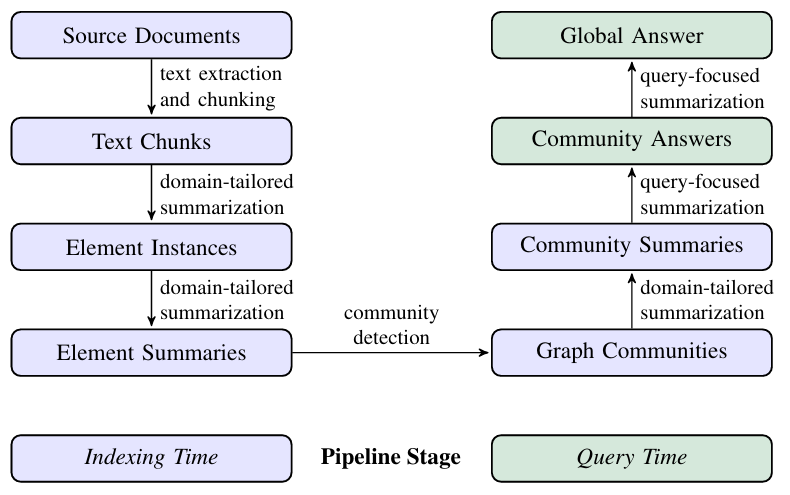
Text Chunking
Dwarkesh provides
links
to the transcripts of his podcast episodes, so it was easy to get the
transcripts of the episode. To preserve the notion of turn-based
conversation, I chunked the transcript text based on each speaker's
speech.
Usually, the podcast transcripts are roughly structured as
More info
Speaker A (timestamp)
# Speaker A's speech
Speaker B (timestamp)
# Speaker B's speech
After chunking the
transcripts
along each speaker's speech, there were approximately 483 chunks. I
analyzed the token length of each chunk.
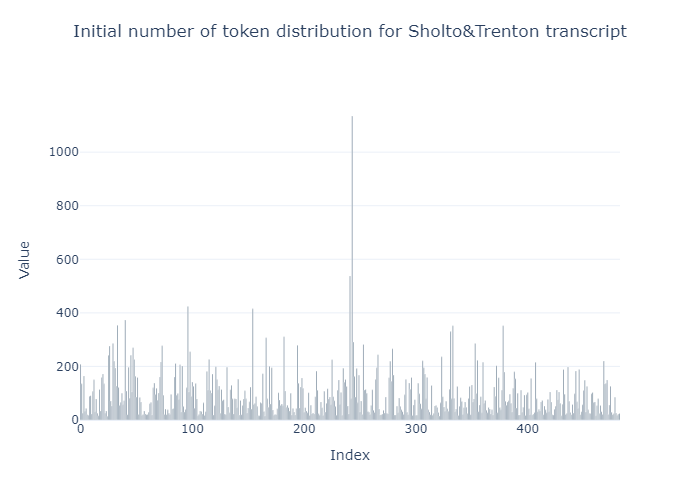
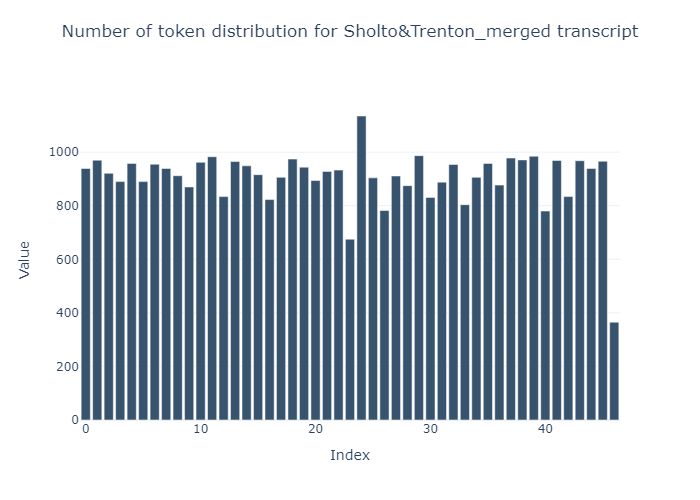
Along the lines of the original paper and for reasons I explain the
next section, I decided to merge chunks, such that each chunk had an
average size of 1000 tokens
483 to
47.
Entity extraction
I hardcoded a list of entity types and manually asked ChatGPT to extraxt entity types from some random sample of chunks, which I then filtered for repeated entity types - this was because extracting the entity type for each chunk was expensive with respect to api calls. I ended up with a list of 33 entity types..
The entity-relationship extraction phase is in two stages.
In the first stage, I prompted the LLM to extract all the entities and relationships from each chunk and output the results in json format. For each entity, I extract the entity_name, entity_type and description. For each relationship, I extract the source entity, target entity, relationship description.
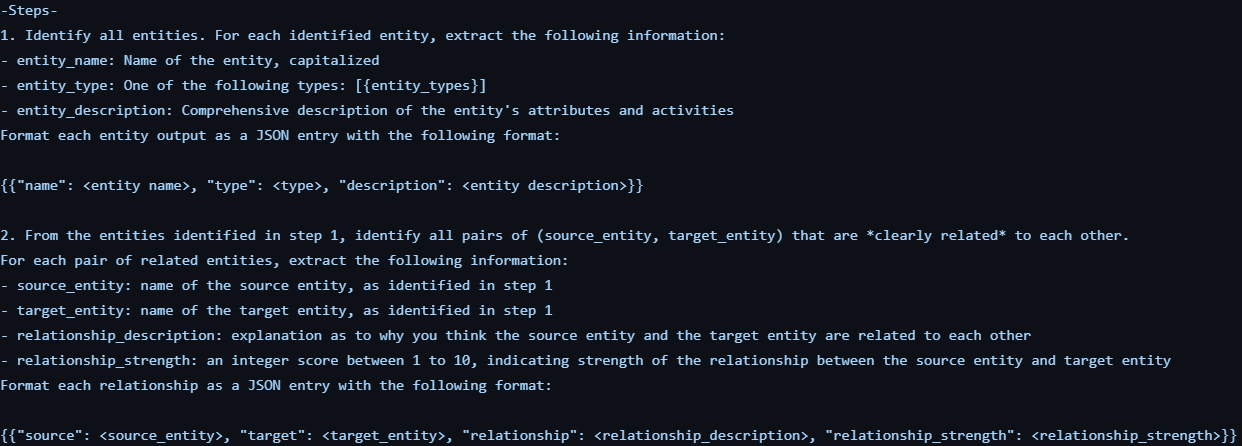
In the second stage, for each entity-relationship json retrieved for
each chunk, I prompt the LLM a second time to check if it has
extracted all the possible entities and relationship. The authors
referred to this as gleaning
A knowledge graph is then
built from the entities and their relationships that have been
extracted. I used the
NetworkX
library to construct the network graph.
A problem here which can be observed from the knowledge graph is that there are a bunch of entities that are not captured in any relatioship with another entity.
In practise, this means that there were two api calls per chunk. In the previous setup where I had > 450 chunks, this would have been close to 1000 api calls but now, I had less than 100 chunks for the whole document.
Graph clustering
Now, we have a graph that's fairly representative of the whole document. A key insight at this stage is that we can group nodes and edges into communities which in principle should be representative of some semantic relatinoship between all the nodes in the community.
In following with the original paper, I used the Leiden algorithm
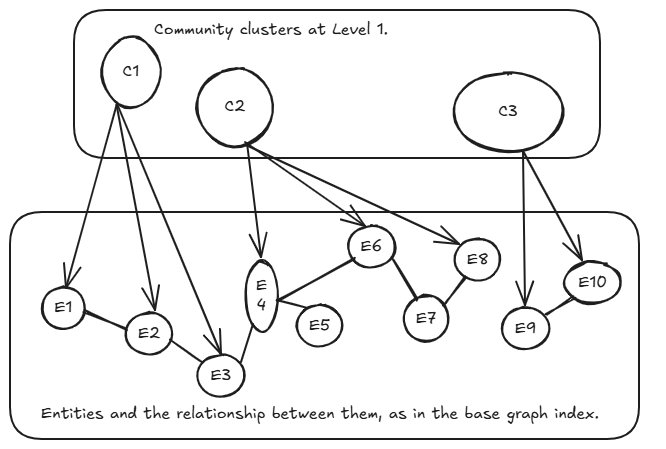
Community summary
My implementation here highly differs from the original implementation. To understand the decision I made, let's delve into what happens when there is a global search on a query.
In the original implementation of global search, when there is a
query, an LLM is used to generate intermediate answer and a relevancy
score to this query,for each community summary. Now,
this is alot of API calls!!.
A neat thing I thought to do, was to generate a list of conclusions or mini-summaries for each community cluster. So instead of just a single community summary, there are a list of insights and conclusions for each community that are generated after the clustering process.
These conclusions are indexed in a vectorDB.
How are queries answered?
For each query, I run a similarity search with all vectors in the
vectorDB from the previous section and I return 15 vectors,
To also be efficient with tokens, I also implemented caching
responses. This means that if a query is sent and at some time later,
a similar query is sent
I did not implement conversation history.
Discussion / Final thoughts
- As mentioned in this discussion , there were some entities without relationships with other entities in the knowledge graph. My thoughts, supported by the paper is that it would be possible to extract more relationships and also entities by running more rounds of gleaning.
- The quality of the generations, from the knowledge graph to the query response would probably be better with more advanced models like GPT 4o.
- Gleaning was able to capture significantly more relationships, but more entities were also introduced to the knowledge graph. I expect that with more rounds of gleaning, this should be resolved neatly. However, it's unclear if more rounds of gleaning will be supported by the context length of the model.
-
The approach of drawing insights from communities and using these
insights to generate response would add alot of latency to the
retrival process when this is over huge datasets, such as the whole
set of all Dwarkesh's podcasts
I plan to work on this sometime in the near future . The rationale is, similarity search is over pieces of text which are way smaller than chunks, but for each chunk, there are 5 - 20 such texts. - Work is not done. I plan to extend this to, at the time of this writing, ~80 Dwarkesh episodes.
Acknowledgements
- Professor Rustam Lukmanov for suggesting the project in the first place, providing feedback and the motivation to do this write-up.
- Kim Fom for useful feedback on writing good code.
- Khush Patel for some advice related to deployment of the admittedly unpolished interface and tradeoffs when choosing a vectorDB.